Optimizing An Image Resizing Service
Background
At one of my past jobs, I took a service that resizes images using imagemagick and tried to find optimizations that would improve throughput and latency. The main focus for me is how to improve the service when there is a cache miss from the CDN. There had been previous attempts to improve the service, and I was able to leverage some of the knowledge gained and do my own analysis to make suggestions for improvement.
The major callout was that the origin servers for many images were controlled by the clients we were serving assets for. It presented risks in terms of unexpected downtime, monitoring, performance, and malicious actors. An architecture and process change was required to address this.
Architecture Changes
As I aluded to, no way would one want to retrieve data directly from an origin provided by the client. An impact of an outage or malicious act is too much risk. Additionally, response times were often around multiple seconds per image. This is what it the system looked like:
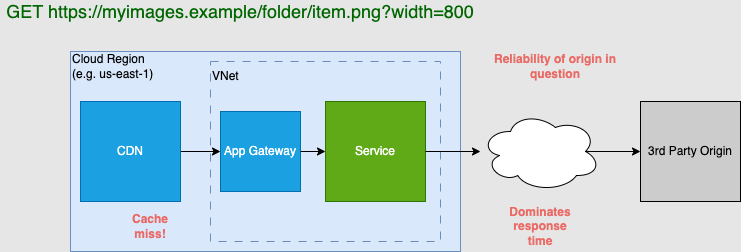
The way to solve the origin problem was to have an ingestion process that will take data delivered from the client and store it in a cloud bucket that is both "nearer" in latency and enable us to ensure uptime, data lifecycle, compliance etc.
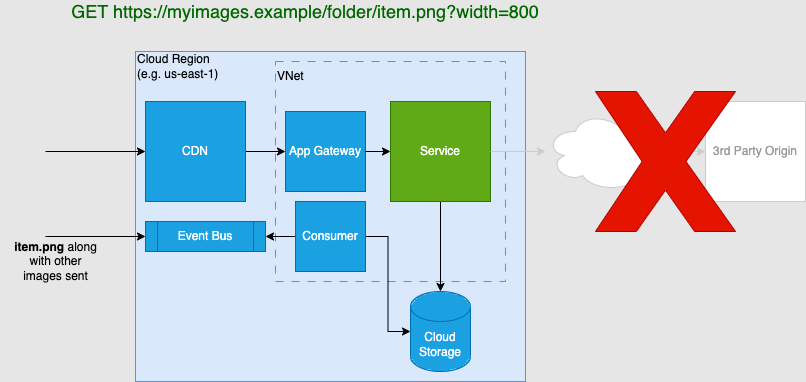
My idea was a separate consumer to handle the ingestion from an event bus that took in the image assets from some ETL scripts that could connect to the clients data. The expected load on the consumer would consist of periodic bulk uploads (10s of thousands). We would want to process these in a reasonable amount of time (order of minutes, but not necessarily as responsive as needed for a web request). This could be done with a Cloud Function, rather than a dedicated service, potentially reducing maintenance. With this, I could more tightly bound the performance of the origin. We could expect most requests to the bucket to have a latency between 50-100ms.
With this, I felt that the problem of dealing with the origin had been solved architecturally. Since I could have confidence in the origin latency, I focused on the implementation of the image optimizer service. That is what the rest of this post will be about.
Implementation Limits and Potential Improvements
I identified three things that could be improved in the image optimization service:
1. Async I/O
Descending down into software implementation highlights the biggest problem with the existing implementation: the code was written with a sync (blocking) I/O model. If we could switch over to async (non-blocking) I/O we could see some significant latency and throughput improvement because a thread could make progress on multiple requests.
2. libvips vs ImageMagick
ImageMagick performance was another area I looked into. libvips claims large improvement over ImageMagick (see: https://github.com/libvips/libvips/wiki/Speed-and-memory-use)
Of course, the image processing performed by ImageMagick and libvips will be CPU bounded rather than I/O bounded. The question is whether the libvips improvements would be substantial enough that we see a difference in any metric.
For this experiment, the image optimizations performed are: - Resize based on the width provided by the request, maintaining the aspect ratio - Use a predefined quality, say 80, for JPEGs - Convert PNG images to WEBP for payload reduction
The consumer could do some of this ahead-of-time, such as converting PNG to WEBP. However, for the time I decided to keep the responsibility of the consumer to the following: - Validating images meet certain criteria (e.g. formatting, size) and reporting rejections in the results - Placing image in Cloud storage and recording the URL for the results report - Produce an event message that will report the result for each image
I expected that certain widths would be most commonly requested, but we could not fully know all possible sizes. For the time being, I decided not to do anything special for any specific image sizes. This is an important point as the service often received requests for a variety of widths, and caused cache misses
3. Temp files?
The original implementation also saved images from the origin to a temp file before processing. Both ImageMagick and libvips allow on to work on images in memory. So it's possible to just read the response from the origin as an in-memory buffer. That would save at least a write and read I/O operation to local disk.
Proof-of-Concept Implementation
All the code can be found at: https://github.com/hevi0/imageopt-example. None of this code is taken from company sources, but instead I re-implemented the relevant portions of the original functionality and the improvements on my own to provide supporting evidence for this document.
Ballpark numbers
Based on the existing traffic, I expected the web-facing service to receive about 1-3% of the traffic since that was the cache miss rate. The CDN layer could receive thousands of requests/sec, meaning about tens of request/sec fall through to the image optimizer. However, I also took into account spikes in cache misses due to actions that bust the cache or having new assets added in bulk. So, I estimated the image optimizer would need to handle around 100 requests/sec at certain times.
Image optimizer
My implementation leveraged pyvips and wand packages to make using libvips and ImageMagick easier with Python. I created six classes in the following combinations:
- Blocking I/O, ImageMagick, Temp file (the baseline implementation)
- Blocking I/O, ImageMagick, No temp file
-
Blocking I/O, libvips, No temp file
-
Non-blocking I/O, ImageMagick, Temp file
- Non-blocking I/O, ImageMagick, No temp file
- Non-blocking I/O, libvips, No temp file
See: imageopt_sync.py and imageopt_async.py
Web server
In order to take advantage of async I/O I would need to have the web server also be built with async libraries and patterns. So my code is split into async and sync versions for the web server. See: imageopt-sync-svc.py and imageopt-async-svc.py
Setup for tests
A handful of images are served using a local running static server (origin-server.py) with some simulated latency. This is meant to be representative of retrieving images from cloud storage with around 50ms-100ms latency. An example URL:
http://localhost:8080/image.jpg
The sync I/O web server, built with Flask, served three endpoints corresponding to the sync versions of the image optimizer:
- http://localhost:8000/sync-imagemagick/image.jpg
- http://localhost:8000/sync-imagemagick-notemp/image.jpg
- http://localhost:8000/sync-pyvips-notemp/image.jpg
The other server, built with Fast API, supports an additional three endpoints for each of the async image optimizer versions:
- http://localhost:8001/async-imagemagick/image.jpg
- http://localhost:8001/async-imagemagick-notemp/image.jpg
- http://localhost:8001/async-pyvips-notemp/image.jpg
I used the locust library to run the load tests.
Establishing the simulated origin performs well enough
Since the tests assume that the origin is performant enough, I had to make sure the server running the origin could handle the expected load. Traffic to the CDN could be expected to be in the hundreds per second, so I assumed we should expect 1000 req/s. With a 1% cache-miss I'm assuming about 10 req/s reach the origin. At the same time, there can be spikes of traffic reaching the origin for various cache-busting scenarios.
With that information, I wanted to check that the origin server be able to handle at least 100 req/sec with the desired response times of 50ms-100ms.
# Run the origin server locally
gunicorn origin-server:app -w 8 -b 0.0.0.0:8080 -k uvicorn.workers.UvicornWorker
# Run with 100 peak users, spawning 20 users at a time, for 5 minutes
locust --processes 4 -f locustfile-origin.py -u 100 -r 20 -t 5m
The load test showed that the simulated origin can comfortably handle 300+ req/s with the desired response times.
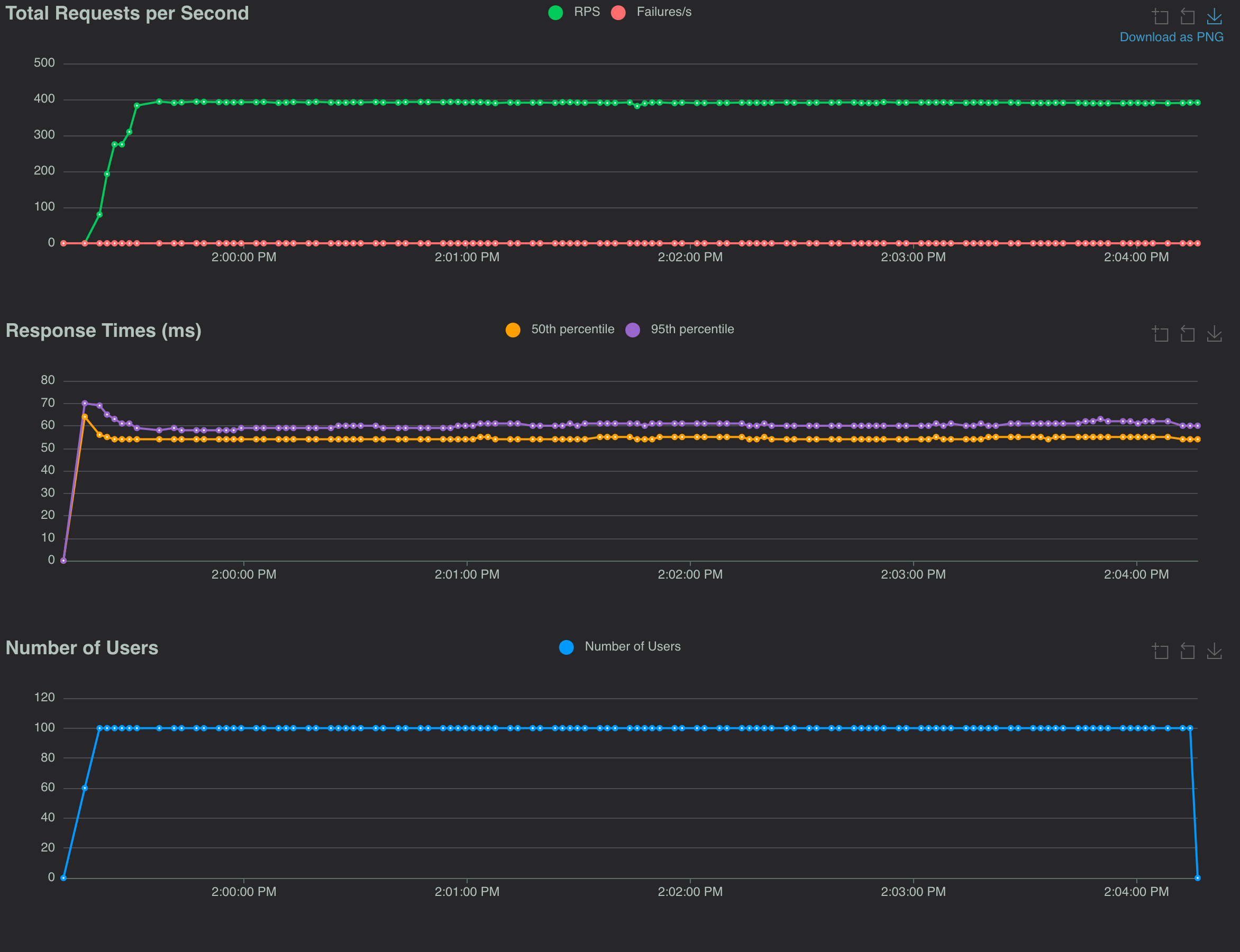
Initial tests provided some evidence for the hypothesis
Once I was comfortable with the state of the origin server, I wanted to get some numbers to understand how the implementations might perform. I gathered a handful of creative commons images to test with. They were a mix of PNG and JPEG, with the max width of 4k and most being between 1000 to 2000 pixels wide. The BUCKET.md file in the git repo lists the images used.
I wrote a script for each version that just cycles through the images on the server and performs the optimizations and resized the images to 640 width.
# Run the origin server locally
gunicorn origin-server:app -w 8 -b 0.0.0.0:8080 -k uvicorn.workers.UvicornWorker
python imageopt-perftest.py
--- SyncIO ImageMagick (wand) with temp file ---
Number of image requests: 6
Runtime: 0.9515715419547632
Est. time spent fetching images: 0.388566255569458
Est. time spent optimizing images: 0.5475120544433594
Peak memory use: 9571380
--- SyncIO ImageMagick (wand) In-memory ---
Number of image requests: 6
Runtime: 0.9289814590010792
Est. time spent fetching images: 0.3765685558319092
Est. time spent optimizing images: 0.5378851890563965
Peak memory use: 9497068
--- SyncIO libvips (pyvips) In-memory ---
Number of image requests: 6
Runtime: 0.6716952080023475
Est. time spent fetching images: 0.37339258193969727
Est. time spent optimizing images: 0.2950451374053955
Peak memory use: 9518517
--- AsyncIO ImageMagick (wand) with temp file ---
Number of image requests: 6
Runtime: 0.6128014160203747
Est. time spent fetching images: 0.3501839981181547
Est. time spent optimizing images: 0.5309076309204102
Peak memory use: 15505432
--- AsyncIO ImageMagick (wand) In-memory ---
Number of image requests: 6
Runtime: 0.6026292919996195
Est. time spent fetching images: 0.35008866601856425
Est. time spent optimizing images: 0.5302791595458984
Peak memory use: 16813259
--- AsyncIO libvips (pyvips) In-memory ---
Number of image requests: 6
Runtime: 0.3599145000334829
Est. time spent fetching images: 0.3418069169856608
Est. time spent optimizing images: 0.2902231216430664
Peak memory use: 15790510
There is an additional set of tests that do a larger batch of requests tha cycle through the images on the server.
--- Bulk SyncIO ImageMagick (wand) with temp file ---
Number of image requests: 100
Runtime: 15.441282250045333
Est. time spent fetching images: 6.33270263671875
Est. time spent optimizing images: 8.865891218185425
Peak memory use: 9515684
--- Bulk AsyncIO ImageMagick (wand) with temp file ---
Number of image requests: 100
Runtime: 9.993378832994495
Est. time spent fetching images: 5.568384534039069
Est. time spent optimizing images: 8.196279764175415
Peak memory use: 13209990
--- Bulk AsyncIO libvips (pyvips) In-memory ---
Number of image requests: 100
Runtime: 6.236263042024802
Est. time spent fetching images: 5.594615249545313
Est. time spent optimizing images: 4.59683084487915
Peak memory use: 9586750
These results show that the best implementation can process images well above 2x faster than the original implementation. This is with the latency from the origin being set to 50ms. The largest benefit comes from the switch to Async I/O (15.44 seconds vs 9.99 seconds), but libvips also makes a significant contribution. I later looked further into how much libvips helps.
libvips concurrency considerations
ImageMagick seems to perform best when left to take advantage of all the cores available. The OMP_THREAD_LIMIT could be used to limit parallel work, but it wasn't helpful for these tests.
However, libvips doesn't necessarily perform better the more threads you add. On an ARM64 processor, it does as shown here:
VIPS_CONCURRENCY=1 python imageopt-perftest.py
--- Bulk AsyncIO libvips (pyvips) In-memory ---
Number of image requests: 100
Runtime: 7.3163577080122195
Est. time spent fetching images: 5.621859626087826
Est. time spent optimizing images: 5.670854568481445
Peak memory use: 9568694
VIPS_CONCURRENCY=2 python imageopt-perftest.py
--- Bulk AsyncIO libvips (pyvips) In-memory ---
Number of image requests: 100
Runtime: 6.486108749988489
Est. time spent fetching images: 5.670763299218379
Est. time spent optimizing images: 4.858407735824585
Peak memory use: 9574103
However, when I tested on an AMD64 using anything above VIPS_CONCURRENCY=1 resulted in worse performance. So for the sake of these tests I kept VIPS_CONCURRENCY to 1 or 2. The documentation from libvips seems to support that increased threads can be counter-productive.
The load tests
With some evidence that libvips and async I/O improving the performance, I went for the load test. I set up some locust scripts to hit the services to a larger degree. I tested on boxes that were not very big and the absolute numbers for response time and throughput are not so important. It's the relative comparisons that I cared about.
Each test consisted of 100 users (ramping from 0-100 at 20/sec) making a request every 0.2 to 2 seconds. I was able to record the max requests/sec and response times for 5 minutes.
Test setup for sync I/O versions
# Run the origin server locally
gunicorn origin-server:app -w 8 -b 0.0.0.0:8080 -k uvicorn.workers.UvicornWorker
# Run the sync I/O image optimization service locally
gunicorn -w 4 -b 0.0.0.0:8000 imageopt-sync-svc:app
With the origin and sync I/O version of the service up, I could run the load tests:
locust -f locustfile-sync.py --tag sync-imagemagick -u 100 -r 20 -t 5m
locust -f locustfile-sync.py --tag sync-imagemagick-notemp -u 100 -r 20 -t 5m
locust -f locustfile-sync.py --tag sync-libvips-notemp -u 100 -r 20 -t 5m
Results from the sync I/O tests
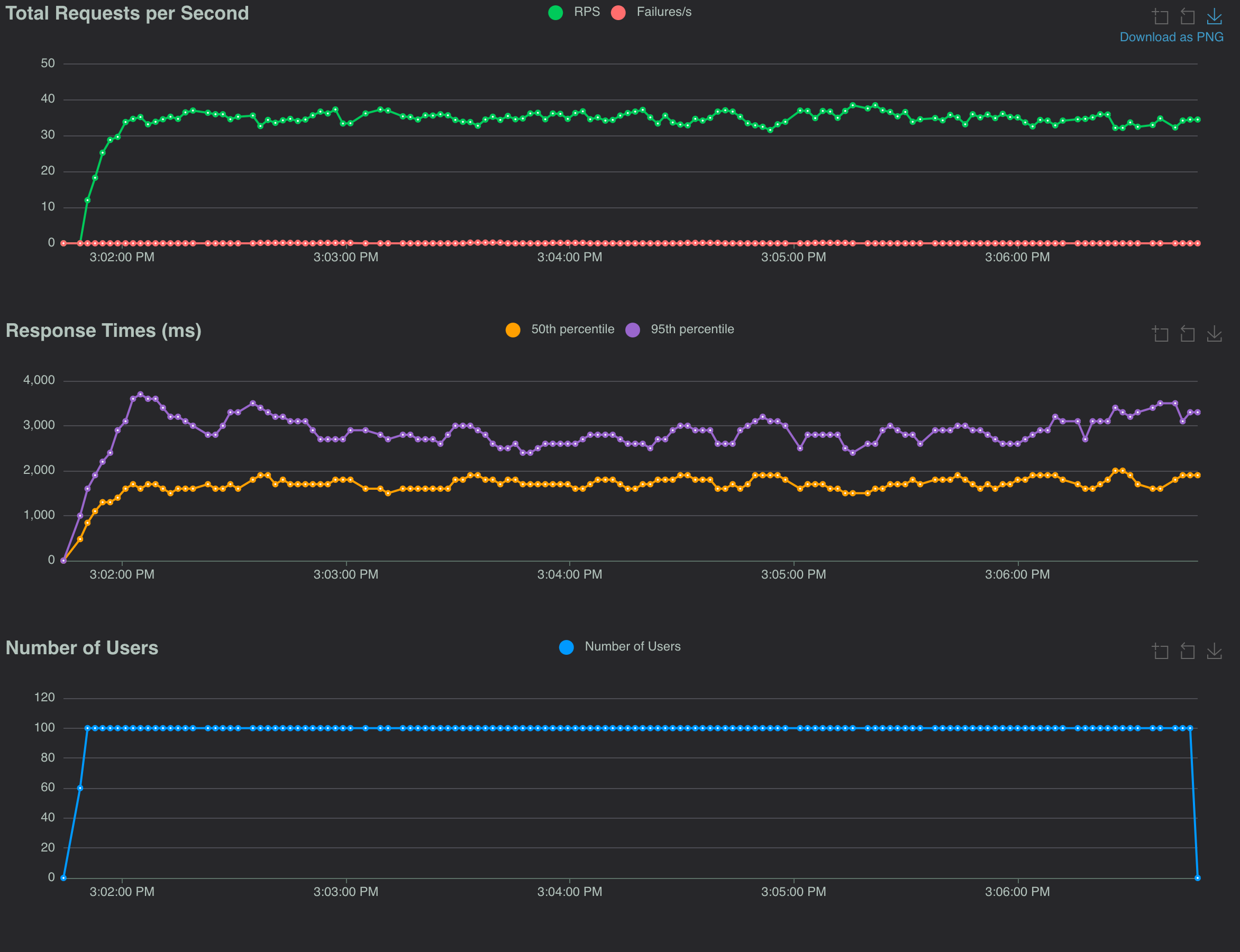
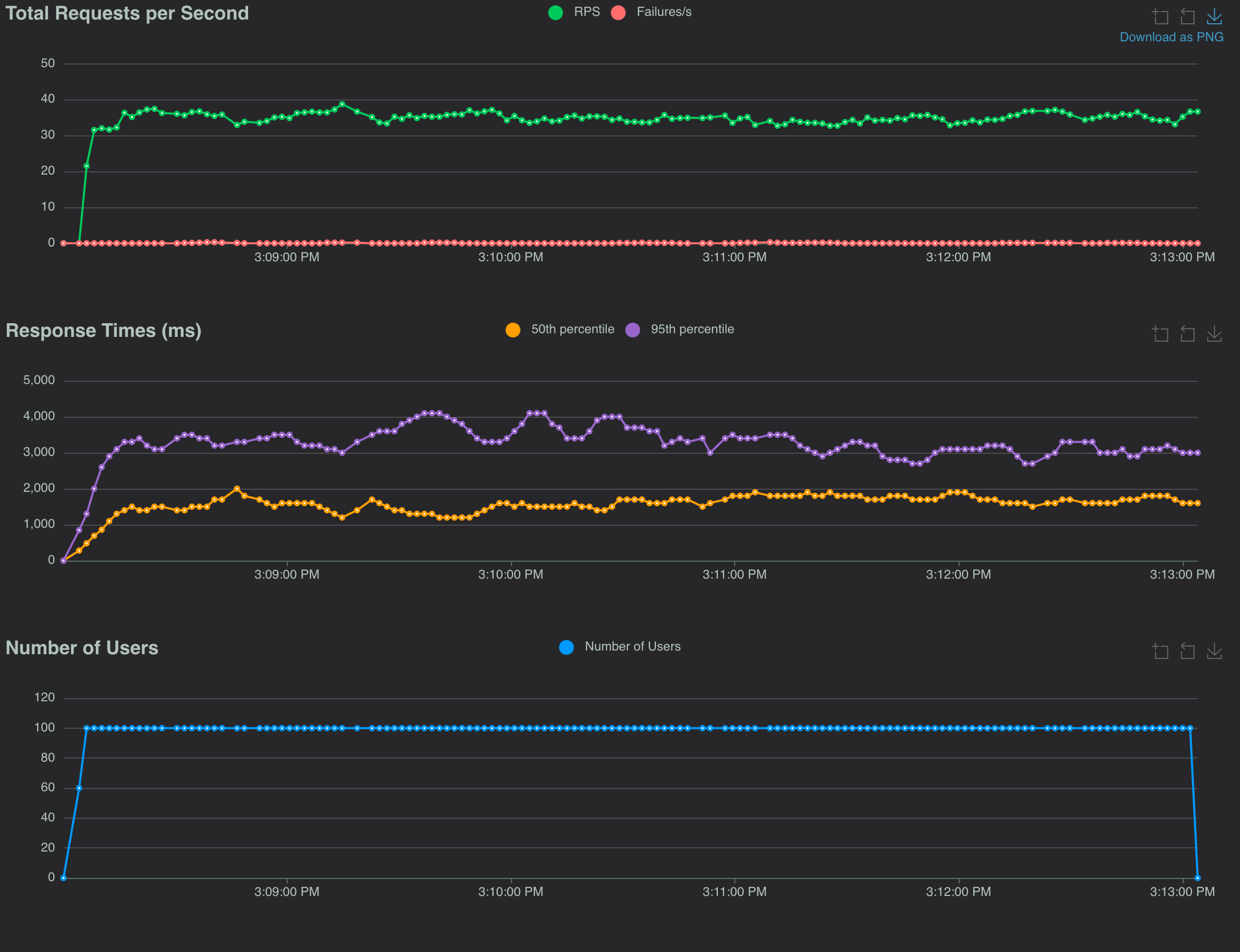
Eliminating the extra read and write I/O by removing the temp file was not so impactful. As it involves local disk, it's probably lost in the variance of the network communication to fetch from the origin. Recalling the latency numbers for reading and writing from an SSD, it's probably around 1ms vs the 50-100ms latency fetching the image. However, this can vary widely depending on the drive. When I tested on another machine I saw bigger impact of reading/writing to local disk.
The CPU-bound work to perform the image operations is enough to be on the order of the fetch response times. This makes the libvips implementation improvements significant. It nearly halves the response times and boosts the requests/sec to the upper 30s.
Test setup for async I/O versions
There was also the async I/O versions, so I set up the origin server and image optimization service for these tests:
# Run the origin server locally
gunicorn origin-server:app -w 8 -b 0.0.0.0:8080 -k uvicorn.workers.UvicornWorker
# Run the optimization service locally
gunicorn imageopt-async-svc:app -w 4 -b 0.0.0.0:8001 -k uvicorn.workers.UvicornWorker
With the origin and async I/O version of the service up, I could run the load tests:
locust -f locustfile-async.py --tag async-imagemagick -u 100 -r 20 -t 5m
locust -f locustfile-async.py --tag async-imagemagick-notemp -u 100 -r 20 -t 5m
locust -f locustfile-async.py --tag async-libvips-notemp -u 100 -r 20 -t 5m
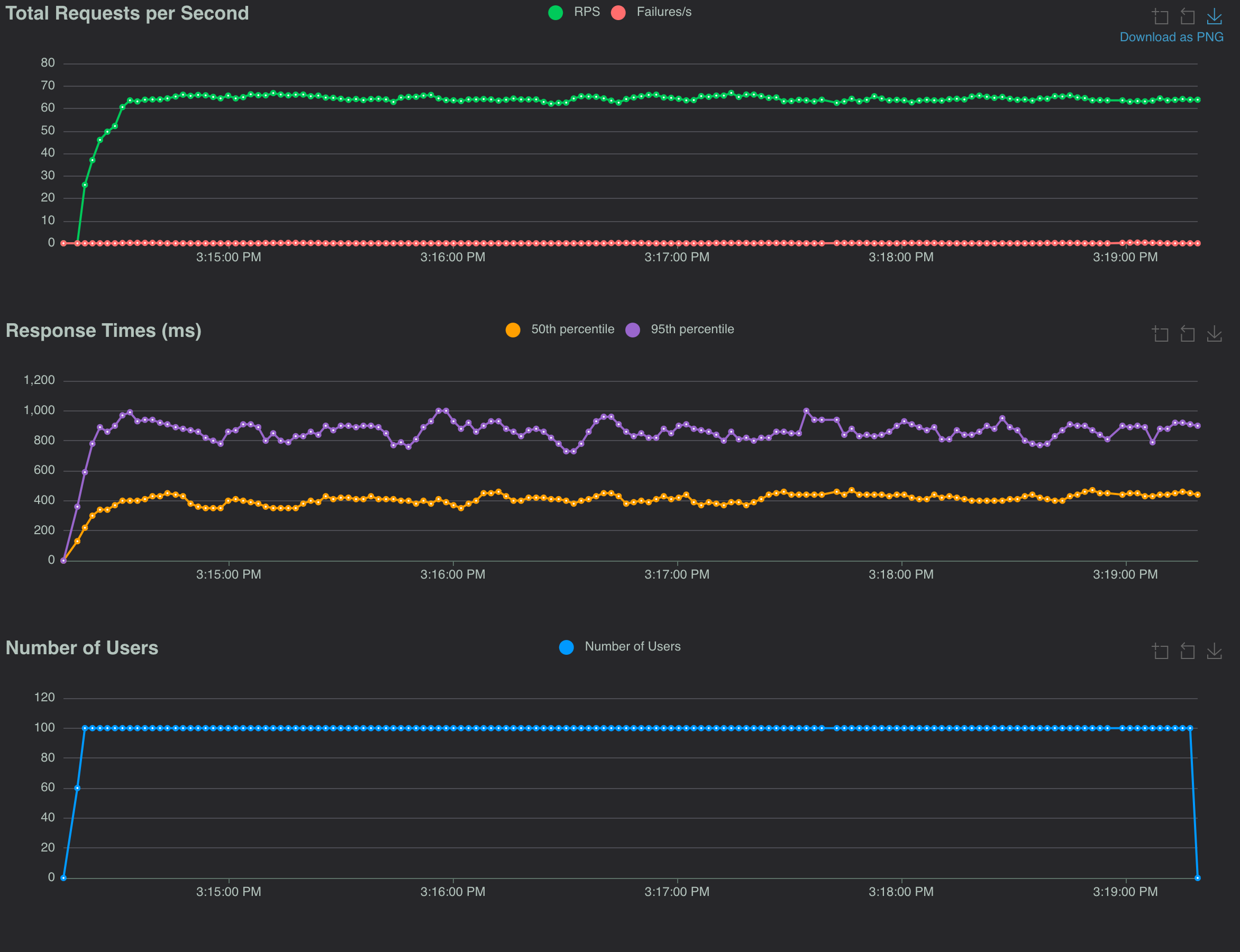
Results from the async I/O tests
There is improvement across all async I/O versions in throughput, which makes sense based on what I knew about advantages of async I/O. Where the sync I/O versions using ImageMagick hovered around 25 req/s, the async I/O versions were able to maintain 35 req/s. It seems there was even some improvement to the response times at least by looking at the 50th percentiles of the response times.
How Much Does Origin Latency Matter?
In my mind, the success of the code changes depended on how much we could keep the origin latency down. While I estimated the origin response times to typically be in the 50ms-100ms range, certainly the 95-percentile could be higher. To confirm the implementation improvements, I updated the origin's simulated latency from 50ms to 800ms.
At such a rate I assumed the improvements from libvips would negligible over ImageMagick, but that Async I/O would still improve the throughput. Here are the load test results:
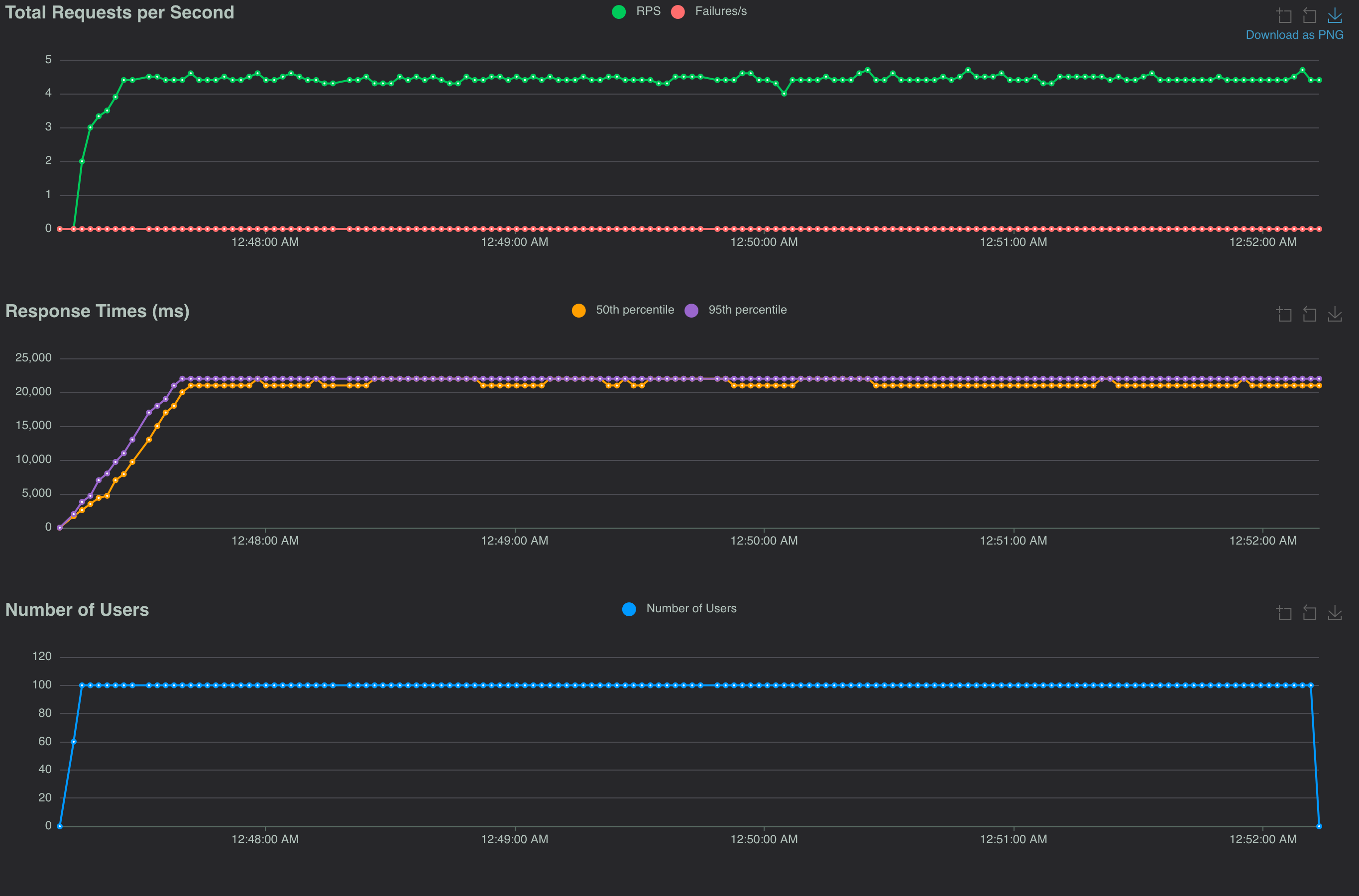
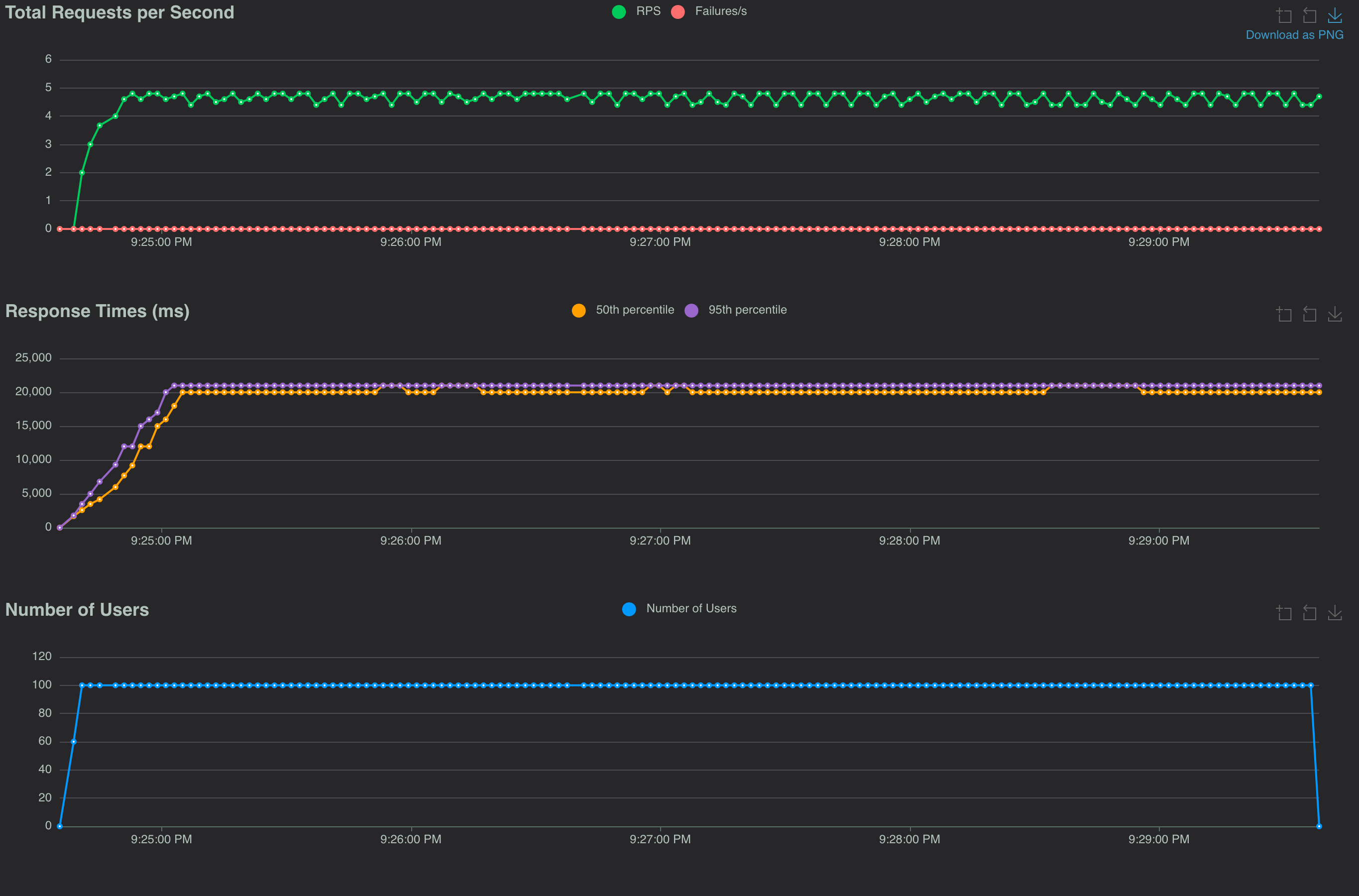
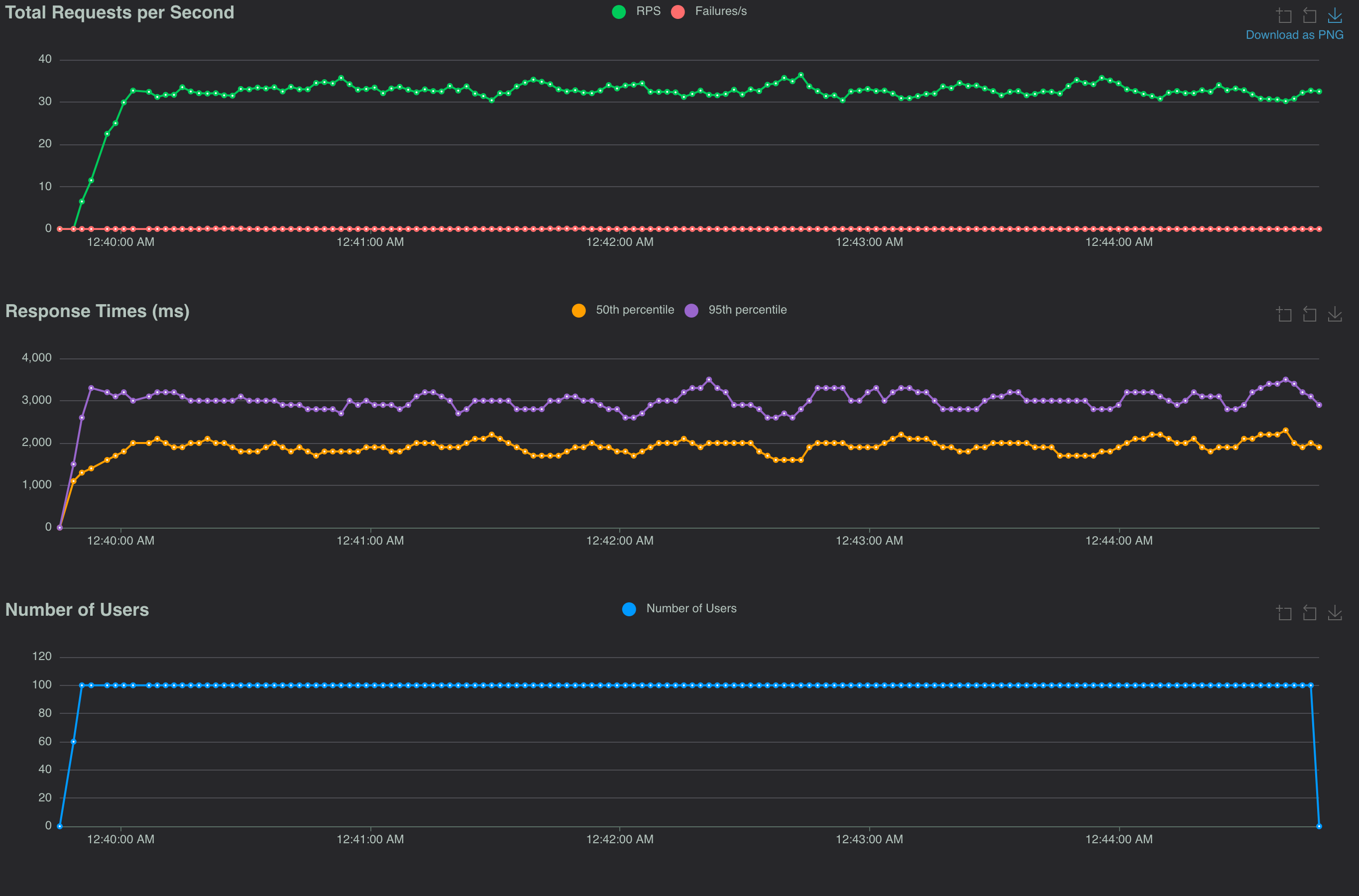
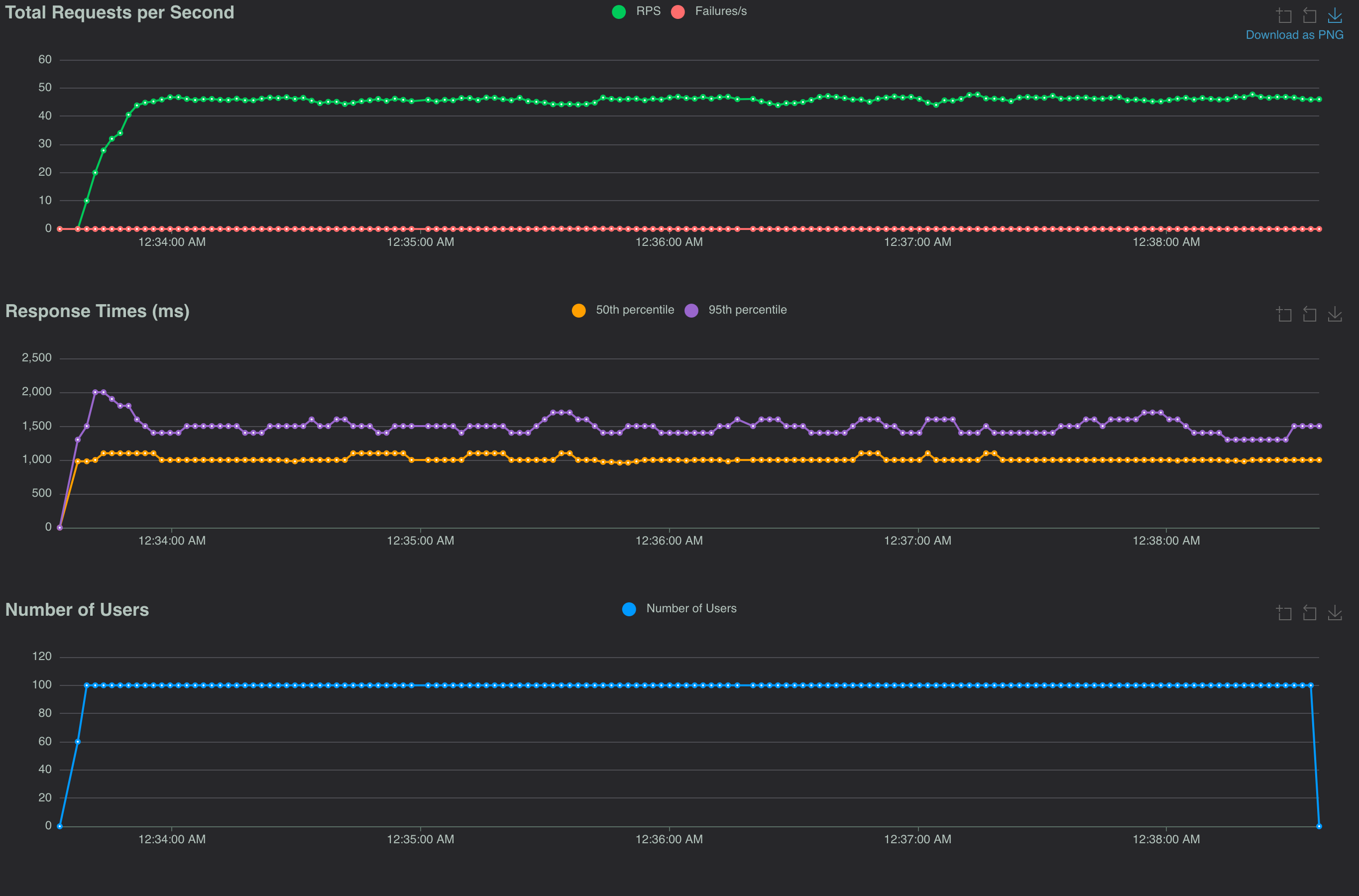
Both the sync versions performed dramatically worse than the async versions. Not really surprising. I diagrammed my mental model of the execution of a single thread processing incoming requests:
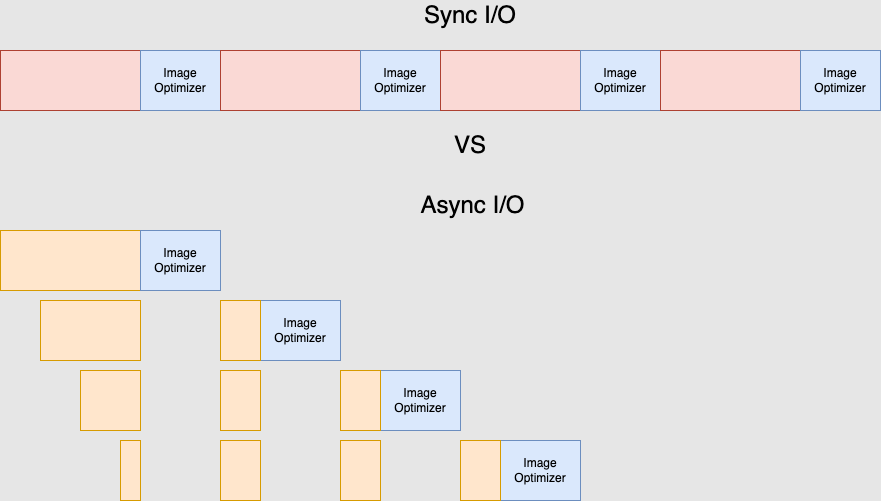
A single thread processing requests will only be able to make progress on one request at a time in the sync I/O model. That's a big deal for the requests down the line as they'll be blocked for a long time. The load tests show this.
The async I/O version will be able to make progress on multiple requests' I/O operations, switching between them as they get the latest chunk of data from their respective sources and doing some work. That's why we see the improved throughput and response times from the async versions.
Until I tried to model this I was a bit puzzled about the fact that libvips still improved things under the 800ms origin latency scenario. It became clear to me that image optimization code (which has no I/O operation) for one request blocked progress on every other request, as shown in the diagram. So, making that section of code as efficient allowed the the thread to go back to making progress on multiple requests quicker. This yielded gains in throughput and response time. The async libvips version processed 10 requests/sec more with half the response times of the async ImageMagick version.
Conclusions
From my analysis I recommended the following changes:
- Move assets into our own cloud storage
- Switch the codebase to an async I/O model
- Replace ImageMagick with libvips
The async libvips implementation halves the cores/instances necessary compared to the original baseline. I ran some additional experiments to support these implementations on a 4-core instance, with 100 requests/sec at a reaonable 200ms-300ms response time. The number of instances that would be required for the baseline version would be around 20-25, whereas the async I/O + libvips version would take around 12 or so.
Not counting the savings, we saw the extreme sensitivity that the baseline implementation has to higher latency from the origin, resulting in far greater blocking of progress on requests and much lower throughput. Here the new async I/O + libvips implementation still provides far better quality of service to the users.